Deploying on Kubernetes #12: Resource Limits
This is the twelfth in a series of blog posts that hope to detail the journey deploying a service on Kubernetes. It’s purpose is not to serve as a tutorial (there are many out there already), but rather to discuss some of the approaches we take.
Assumptions
To read this it’s expected that you’re familiar with Docker, and have perhaps played with building docker containers. Additionally, some experience with docker-compose is perhaps useful, though not immediately related.
Necessary Background
So far we’ve been able:
- Define Requirements
- Create the helm chart to manage the resources
- Add the MySQL and Redis dependencies
- Create a functional unit of software … sortof.
- Configure some of the software
- Configure the secret parts of the software
- Install/upgrade the software automatically with release
- Supply the required TLS resources
- Expose the application to the public via a service
- Add health checking to the service
- Add annotations to the service, pod
Friendly co-location
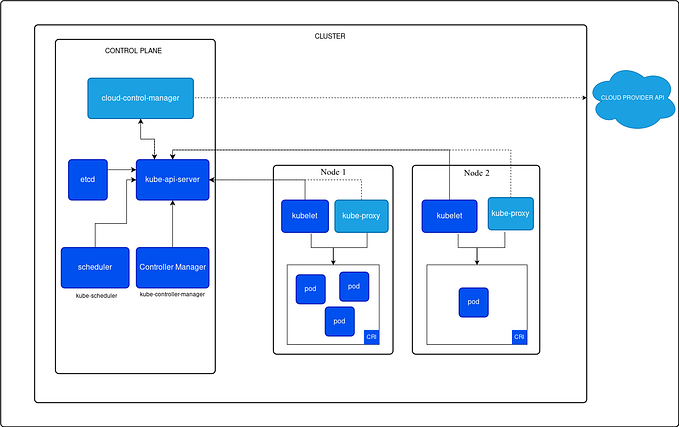
One of the fundamental value propositions for Kubernetes is that it allows using much more of a single machine. Given a cluster of 10 machines, we might be able to pack them to be used at 80% capacity all the time. Additionally, we might be able to run 30 services across these 10 machines, with those services not interfering with each other in any significant way.
By default, Kubernetes is designed to pack as many services onto as a few computers as possible. Generally, this makes sense — it allows maximal efficient, and applications are not typically all competing for CPU but rather have spiky usage patterns.
However, there is invariably a limit to how many applications can be packed onto a single machine. In order to understand how many application should be scheduled, Kubernetes allows assigning each workload an amount of “resource”. It is then able to solve a couple of problems:
Bin Packing
The most obvious problem that it solves is the bin-packing problem. Failure constraints aside, we need to know how many of a given set of services can run on a machine.
By assigning each replica of a service a resource constraint (for example, “100m”) and querying how much of a resource constraint is available on a machine (for example, 2000m) we know how many of this application can run on this machine.
Quality of Service (QOS)
Though I found this initially intuitive, allocating resource to workloads also allows us to determine which applications should be available under all circumstances, versus workloads that are perhaps more flexible.
To understand how this works, it’s first important to understand that there are actually two different kinds of allocation to a kubernetes workload:
- request: How much should be available
- limit: How much a given pod can use
Importantly, it’s possible to have limits that exceed the max capacity of the node. So, we could have several pods:
- MySQL (request: 500m, limit: 1000m)
- Redis (request: 500m, limit: 1000m)
- Kolide (request: 100m, limit: 250m)
in conjunction with a single node, with a capacity of 2000m. That implies that we are over-committed:
(1000m + 1000m + 250m) — 2000m = -250mIn the case all applications are simultaneously busy, something will have to give. This can go a couple of ways:
- The kernel on the node handles this by diving up what resources are available fairly, based on the requests of the worklods
- The kernel starts killing stuff that has the lowest quality of service until enough room is available.
Given the above knowledge, we can work out what the levels of quality of service should be:
- No request, No limit: Low
- Request, No Limit: Medium
- Request, Limit: High
So applications will be killed in the order of “1”, “2” and then “3”. And thus we have QOS!
Our Services
We have three services that make up our application:
- Redis (a dependency)
- MySQL (a dependency)
- Kolide
Luckily, a pattern of expressing the resource constraints already exists for Helm; we do not have to implement either Redis or MySQL — though the user of the chart can modify them later.
Indeed, our starter chart has quality of service by default!
# templates/default.yaml:63-69 args:
- "fleet"
- "serve"
- "--config"
- "/etc/fleet/config.yml"
resources:
{{ toYaml .Values.resources | indent 12 }}
The last line is similar to our previous annotations line — it picks up the values directly out of Values.yaml:
# values.yaml:116-122resources:
requests:
cpu: "100m"
memory: "512Mi"
limits:
# cpu: "100m"
# memory: "512Mi"
In the example above, we can see that the kolide chart has both CPU and memory defined in the resource requests. These are the most common requirements, with disk space currently handled by requesting a disk of appropriate size from the provisioner.
The above would put it in the QOS class of “medium” — important, but not super mission critical. That seems reasonable. However, let’s check the current usage against what’s used in the custer:
$ kubectl top pod
NAME CPU(cores) MEMORY(bytes)
kolide-fleet-fleet-68c766dd57-76tdw 4m 25MiHmm. Doesn’t seem like it’s doing much. However, CPU and memory are pretty cheap. Let’s give it 100m (1/10th of a CPU) and 256Mi:
resources:
requests:
cpu: "100m"
memory: "256Mi"
limits:
# cpu: "100m"
# memory: "512Mi"After our update, we can see that this is applied successfully:
$ kubectl describe pod kolide-fleet-fleet-56b5c7f7c9-gkwpl #15-16,31-33...
Containers:
fleet:
...
Requests:
cpu: 100m
memory: 256Mi
...
That’s it! Given the work implemented in the starter chart, resource limits were comparatively simple to implement.
That’s it for the technical side of this post! I will tidy and document the repository, and submit it to the repo to the charts repo for review.